Tactic-toe (Software)
Please first see the overview article to learn about tactic-toe
Introduction
This article will explore how I solved tactic-toe and created an AI that plays the game perfectly.
I will first explore minimax algorithm and my attempts of making it to work. Then, with the context of minimax, I made a better solution that solves the game. Using it, I made and AI that plays the game perfectly with an online version of the game for demonstration.
Minimax
One of the most common ways of calculating the best move in a turn based game is with the minimax algorithm.
To put it simply, the algorithm works by having one player trying to maximize the score, while the opponent tries to minimize the score (thus “minimax”). It goes through to each possible moves, look ahead and evaluates the next possible moves by the opponent. The algorithm assumes both player chooses the most favourable move in a situation and so the resulting end state is propagated back up to inform if the move results in a good position for the current player.
I tried my best to explain it in my own words, but I think this video below explains it well with a chess engine example.
Its crazy how much optimization that goes into making chess engines, and yet chess has still not yet been solved even with superfast computers.
If you’ve ever taken a course on AI, chances are you might have used minimax to make an AI for tic-tac-toe. That’s indeed what I did when I took CS50ai an online course by Harvard. I’d recommend everyone reading this to take on that course. It covers all kinds of AI types not just LLMs.
Starting off with the same tic-tac-toe code from the course, I modified the code to the new “infinite” game logic. Then, when I ran the original AI with the new game, it fails and crashes.
To see why it fails, here is the basic implementation of minimax algorithm in pseudocode taken from wikipedia.
function minimax(node, depth, maximizingPlayer) is
if depth = 0 or node is a terminal node then
return the heuristic value of node
if maximizingPlayer then
value := −∞
for each child of node do
value := max(value, minimax(child, depth − 1, FALSE))
return value
else (* minimizing player *)
value := +∞
for each child of node do
value := min(value, minimax(child, depth − 1, TRUE))
return value
(* Initial call *)
minimax(origin, depth, TRUE)
Few important to keep in mind when using minimax:
- Recursive: It is a recursive function because it calls itself in the function.
- Heuristic function: When it reaches the end (or terminal) node, it has to return the heuristic value of the node, typically determined by a heuristic function that evaluates the “score” for a given state.
Recursion
One big problem caused by the recursion, if the game can infinitely repeat (which is the case for tactic-toe), it will get stuck and never reaches the end state, resulting in a crash.
Initially, I did not limit the search depth like shown in the example code above, which resulted in the first crash. After realizing the cause and implemented the depth limit, it no longer crashes. However, it is not that simple, unfortunately.
How would you know how deep your search algorithm should go for in order for it to find the best move? The time it takes for the function to execute will increase exponentially as it goes deeper, the branches expand more and more. If it’s too small, then it might’ve not looked deep enough to be able to find the right move.
As expected, the AI does not perform well when I played against it as it kept losing. Even with a very high depth, it was taking few minutes to calculate and still lost. This is partly explained by the second point, the heuristic function.
Heuristic Function
Heuristic function evaluates how good or bad a state of the game is and typically with the normal tic-tac-toe, you would only check for the end states (if any of the player is winning or draw if no spaces are left). This works perfectly fine in this case because the heuristic function is only called when the game ends (either win or draw).
This becomes a problem for an infinite game since if the function is terminated early (by the depth limit), it has to determine how good a state is for a player when the game has not ended yet.
One way, you could say that if it reaches the depth limit, it’s probably a “draw” state as it should’ve already looked through the optimal moves, which are higher up on the branch. I tried this, and I found out that it doesn’t work that way as the AI will always think that there is a “draw” further deep even though its already in a losing state.
Another approach is to evaluate the state purely from the current position of the marks on the board. For example, player with middle mark has better chances than the marks in the corner. This is actually how chess engines evaluate its position (but in a more clever way). However, there are few issues with this approach.
There’s no game theory to support that one square is better than the other. Unlike chess where you have piece values and best squares for certain pieces in theory. Sure, normal tic-tac-toe has its theory/strategy, but if you played the tactic-toe version yourself you would know the strategy is very different. So, I would have to figure it out and hardcode it myself. It’s not impossible to do, but the limitation is that the AI will only be as good as me which is not good enough in my book.
Optimization Attempts and Fixes
Surely minimax should work right? Here are some other things that I have tried to make it work:
Depth based Heuristic
Another problem with the original heuristic is that it only sees the final outcome, whether it will win or lose at the end. What that means is that if it knows that if it’s in a losing state it won’t try to defend and just make random-ish moves without trying to defend because it knows, it will only either lose or win, the heuristic does not reward for staying alive longer.
So, what I did is, adding depth into the heuristic function called utility() as shown below:
def utility(state, depth):
"""
Returns the value of the board, also based on depth the of the search (higher depth means less steps to get to the position)
"""
winPlayer = winner(state)
if winPlayer == X:
return 1 * depth
elif winPlayer == O:
return -1 * depth
else:
return 0
Now the score of a state also depends on how quick the state can be reached. This dramatically improved how good the AI was, but it still loses sometimes.
Duplicate State Detection
One of the first ways that I thought of fixing the recursion depth issue is to keep track of the states already been evaluated before and returning a draw if the same state is detected. Because if you think about it, it can only get stuck if it goes in a loop that returns to the original position. So, if you can get back to the original position, it must be a drawing position right?
def eval(board, path):
"""
Recursive minimax function
"""
if boardHashed in path: # Return 0 if the state its already discovered previously
return 0
### rest of the minimax logic
for move in available_moves:
path.append(board) # Add the current board to the list of evaluated boards in the path
eval(new_board, path) # recursive call with the new path list
After I tried this, it still had recursion limit error. Turns out, if you think about it even more, it would not work as the repeating loop can be in any different sizes, and it could go through all the states before detecting a repeating state. A better way of doing this, as I later tried is with transposition table.
Negamax
There is another version of minimax where it is basically just flips the scores of each player by taking the negative score of a state, thus the name - negamax. This was no better than the original normal minimax in this case but I thought I might just give it try because the wikipedia page gives an example of using negamax with transposition table.
Alpha-Beta Pruning
The most common optimization technique for minimax is what’s called alpha-beta pruning. It is very simple and yet very clever. The main idea is that if the algorithm detects that the branch its exploring, can only result in worse position than what it had discovered before, it will just “prune” that branch and skips it. The video at the start explains this very clearly.
This if implemented correctly, it improves the execution times a lot as it can just skip most branch if its worse anyway. The only downside to this is that it is harder to debug the program as it introduces alpha and beta variables which lets just say, it is very hard to get wrap my head around. Might just be a skill issue honestly.
Transposition Table
The main idea of keeping track of the discovered states always stuck to me as it can potentially solve all the issues.
If it can just remember the score of each state as it is exploring the branches, it would fix the depth issue as it won’t get stuck in an infinite recursion loop as it eventually will return to a discovered state. It would also provide a list of states, and the scores can prove that the game is solved.
The algorithm in pseudocode taken from wikipedia shown below:
function negamax(node, depth, α, β, color) is
alphaOrig := α
(* Transposition Table Lookup; node is the lookup key for ttEntry *)
ttEntry := transpositionTableLookup(node)
if ttEntry.is_valid and ttEntry.depth ≥ depth then
if ttEntry.flag = EXACT then
return ttEntry.value
else if ttEntry.flag = LOWERBOUND and ttEntry.value ≥ beta then
return ttEntry.value
else if ttEntry.flag = UPPERBOUND and ttEntry.value ≤ alpha then
return ttEntry.value
if depth = 0 or node is a terminal node then
return color × the heuristic value of node
childNodes := generateMoves(node)
childNodes := orderMoves(childNodes)
value := −∞
for each child in childNodes do
value := max(value, −negamax(child, depth − 1, −β, −α, −color))
α := max(α, value)
if α ≥ β then
break
(* Transposition Table Store; node is the lookup key for ttEntry *)
ttEntry.value := value
if value ≤ alphaOrig then
ttEntry.flag := UPPERBOUND
else if value ≥ β then
ttEntry.flag := LOWERBOUND
else
ttEntry.flag := EXACT
ttEntry.depth := depth
ttEntry.is_valid := true
transpositionTableStore(node, ttEntry)
return value
(* Initial call for Player A's root node *)
negamax(rootNode, depth, −∞, +∞, 1)
It is indeed more complex now that there is αβ pruning with transposition table. Turns out, you can’t simply store the calculated states if you are also using αβ pruning because the states that are “pruned” are not fully explored yet. Therefore, if you store it directly, the score might be incomplete as all some part of the branch has been pruned last time its calculated. Plus, the same problem happened where it does not solve the depth problem, so the depth parameter is still needed.
The fix to this is to store more than just the score in order for it to recalculate the next time the function runs again. Not gonna lie, its very confusing and most of my time was spent trying to get this to work. Eventually, I did get something very promising.
The final version of this was able to play decently with a high enough calculation depth. HOWEVER, it takes minutes to run for each move, and it was giving a symmetrical move a different value of scores when it should’ve had the same value as it is essentially the same if you rotate the board. This indicates that it is still not perfect.
Fundamental Problem
Even if I could fix the problems with minimax and get it to work perfectly, I will still not be able to verify if it is making the best moves. At the end, even I couldn’t beat it, but it’s still not conclusive if its making perfect moves. I could make it versus itself, but that would take too long.
There is also no way of knowing what’s the search depth that should be used. In theory, there could be a better move sequence may not be discovered yet because of the search depth was not sufficient.
So, I decided to take an entirely new approach.
The Solution
I always knew that the easiest way to prove that the AI is perfect if it analyses all possible states of the game. However, minimax doesn’t really fit this purpose since it was meant to calculate the best move as the game progresses, and not analyse the entire game.
What if I just brute force it by analysing all possible states of the game and calculate backwards from the end game states?
So I came up with a these steps:
- Get all the possible states of the game
- Assign score of 0 to all states by default.
- From all the possible states, get only the end states and give it the highest score (+ve for X winning, -ve for O winning)
- Iterate through all possible state, and get all of its child states (resulting states from available moves)
- If the state is the maximizing player’s (X) turn, get the maximum score (minimum for O) from its children states.
- Apply the current state’s score = -1 from its maximum child score
- If there is a change to the current state’s score, +1 to the amount of changes.
- If changes is non-zero, loop back to 4 until there are no more changes (it converges).
It might just be easier to show the actual code I made in python:
def evaluate_best_moves(states_encoded):
# Base Scores
MAX_SCORE = 100
MIN_SCORE = -100
DRAW_SCORE = 0
scores = {}
# Create a lookup for the children of each state to avoid re-calculating
# children = {encoded_state: set((move1, child1), (move2, child2), ...)}
children = {}
for state_encoded in states_encoded:
state = decodeState(state_encoded)
# Only calculate children for non-terminal states
if winner(state) == 0:
children[state_encoded] = set([(move, get_canonical_form(result(state, move)["board"], result(state, move)["turn"])) for move in get_moves(state)])
else:
children[state_encoded] = set()
# 1. Init scores
state_winner = winner(state)
if state_winner == X:
scores[state_encoded] = MAX_SCORE
elif state_winner == O:
scores[state_encoded] = MIN_SCORE
else:
scores[state_encoded] = DRAW_SCORE
# 2. Iteration until convergence
iteration_count = 0
while True:
iteration_count += 1
print(f"Starting iteration {iteration_count}...")
# Keep track of changes in a single pass
changes = 0
# Go through every state that is not a terminal win/loss
for state_encoded, children_data in children.items():
if len(children_data) == 0:
continue
state_children_encoded = [data[1] for data in children_data]
# Get the current scores of all children states
# Note: We use the scores from the *previous* iteration to calculate the new ones
child_scores = [scores[state_child_encoded] for state_child_encoded in state_children_encoded]
# Apply the minimax principle
best_child_score = 0
if decodeState(state_encoded)["turn"] == X:
best_child_score = max(child_scores)
else: # Turn is O
best_child_score = min(child_scores)
# Adjust the score based on depth
new_score = 0
if best_child_score > DRAW_SCORE: # It's a path to a win
new_score = best_child_score - 1
elif best_child_score < DRAW_SCORE: # It's a path to a loss
new_score = best_child_score + 1
else: # It's a draw
new_score = DRAW_SCORE
if scores[state_encoded] != new_score:
scores[state_encoded] = new_score
changes += 1
print(f"Iteration {iteration_count} finished with {changes} updates.")
# 3. Convergence Check
if changes == 0:
# pprint(children)
print("Scores have converged. Halting.")
break
You could think this of almost like a reverse minimax, where it instead analyses from the end states and propagates back up to the initial state.
As for the algorithm name, I couldn’t find a formal name for this algorithm, but it is technically similar to retrograde analysis in the world of chess. I would call it reverse minimax with my own decaying logic for best moves prioritization.
As I mentioned, its basically like brute-forcing the entire game, so technically it can solve any 2 player game given that you have enough memory to store all possible states of the game. More complex games like chess would have billions of unique game states so it’s not really groundbreaking algorithm or anything crazy. But, maybe I’ll try to apply it to other games in the future.
Symmetry Optimization
As just mentioned, this algorithm has to store all possible states in memory. Thus, if we can reduce the amount of state by eliminating duplicate symmetrical states, that can significantly reduce execution time and memory required. Luckily, tic-tac-toe or even tactic-toe has a board that you can rotate/flip/mirror and essentially be the same board (state).
Imagine if we have a standardized way of representing a state of the game that would eliminate any symmetrical duplicates, with that way, any duplicates will be automatically detected. I.e., if two symmetrical states are converted to the standardized format, they will both be detected as the same state.
The way I have implemented this is by having a function called get_canonical_form() that converts any state to its canonical (standardized) format.
TRANSFORMATION_MAPS = (
# (0, 1, 2, 3, 4, 5, 6, 7, 8), # 0: Identity
(2, 5, 8, 1, 4, 7, 0, 3, 6), # 1: Rotate 90 degrees CC
(8, 7, 6, 5, 4, 3, 2, 1, 0), # 2: Rotate 180 degrees CC
(6, 3, 0, 7, 4, 1, 8, 5, 2), # 3: Rotate 270 degrees CC
(2, 1, 0, 5, 4, 3, 8, 7, 6), # 4: Flip horizontally
(0, 3, 6, 1, 4, 7, 2, 5, 8), # 5: Flip Horizontally -> Rotate 90 CC (TL / BR Sym)
(6, 7, 8, 3, 4, 5, 0, 1, 2), # 6: Flip Horizontally -> Rotate 180 CC (Vertical Flip)
(8, 5, 2, 7, 4, 1, 6, 3, 0), # 7: Flip Horizontally -> Rotate 270 CC (TR / BL Sym)
)
def get_canonical_form(board, turn):
# -- getting the canonical state form -- #
min_state_encoded = encodeState(flatten_board(board), turn)
for transform_map in TRANSFORMATION_MAPS:
flat_board = flatten_board(board)
transformed_board = [flat_board[i] for i in transform_map]
transformed_state_encoded = encodeState(transformed_board, turn)
if transformed_state_encoded < min_state_encoded:
min_state_encoded = transformed_state_encoded
return min_state_encoded
encodeState() essentially converts a state into bytes form. The canonical function will try out all transformations, and the resulting transformed state with the lowest value in bytes is the final canonical form.
def encodeState(board_flat, turn):
location_arr = boardToPosition(board_flat)
# turn_sign = 1 if (turn_sign == 1) else 0
encoded_bytes = bytes([
(location_arr[0] << 4) | location_arr[1],
(location_arr[2] << 4) | location_arr[3],
(location_arr[4] << 4) | location_arr[5],
1 if (turn == X) else 0
])
return encoded_bytes
How the states are converted to bytes form will be explained in the firmware article.
Result
It only took a few seconds for the algorithm to calculate all 16030 unique game states. Which is much better than my minimax attempt.
Each state has its scores ranging from -16 to 16, with 0 being a draw and +-16 are the winning states. After a move is made, the score increases (if best move is played). From that, it is easy to determine the best moves by just comparing scores of all the child states.
With that implemented the AI played the game perfectly
I am confident that it is playing perfectly as it has explored all the possible states of the game. Plus, my friends and I couldn’t even beat it. It always seems that you can still win when in reality the AI is already winning. It’s crazy that there are states with (score == +-1) where the AI will eventually win in 15 moves if defended perfectly.
Winning Strategy
From an empty board, the first player will always win if played perfectly, and it takes at least 13 moves or less from the start to win, shown below:

So, what is the winning strategy? How do I win against another player?
The answer is I don’t know. I could come up with a few basic strategies, but I think it is more interesting to see my creation is better than myself. This AI is much smarter than what I could achieve hard-coding a strategy myself. Plus, it could also be adapted to other 2 player games which you can’t say the same for a hardcoded AI.
You could use the moves from my AI to come up with your own strategies. I think its more fun this way. Definitely not gatekeeping the best strategies for myself :)
What I can tell is that from an empty board, the centre and corner squares results in a draw. The middle side squares are the only winning starting moves. With this knowledge, and enough tries you can win against the AI.
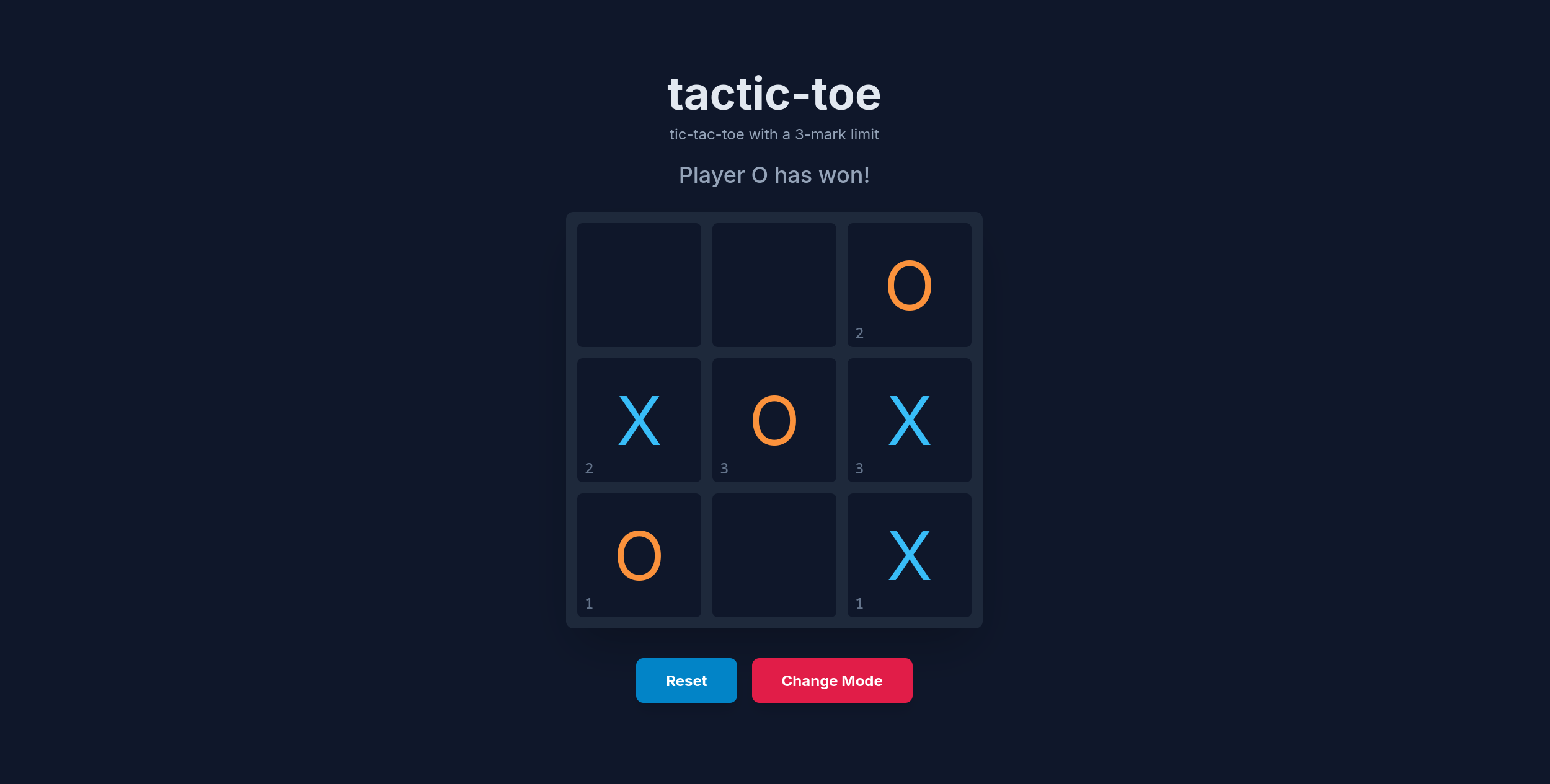
Online Web Version
To present my AI, I decided to make a web version to easily share with people. Not gonna lie, I vibe coded most of the assets, but the game logic was made by me.
Play tactic-toe online:
The way the web version works is it just has a JSON file with all the best moves and plays a random move out of all the best moves. I couldn’t be bothered to reimplement the calculation algorithm in JS.
If you are curious, open the console on the online tactic-toe (Ctrl+Shift+I) and it will show you the precalculated state score after a move is placed.
Source Code
All the code used including the web game HTML are all open source in my public GitHub repo. Feel free to try it out or even improve it and I challenge you to beat my AI.
Link to the GitHub repo: github.com/Amrlxyz/tactictoe